
jets虚拟货币
2023年06月16日 23:52

欧易okx交易所下载
欧易交易所又称欧易OKX,是世界领先的数字资产交易所,主要面向全球用户提供比特币、莱特币、以太币等数字资产的现货和衍生品交易服务,通过使用区块链技术为全球交易者提供高级金融服务。
前言
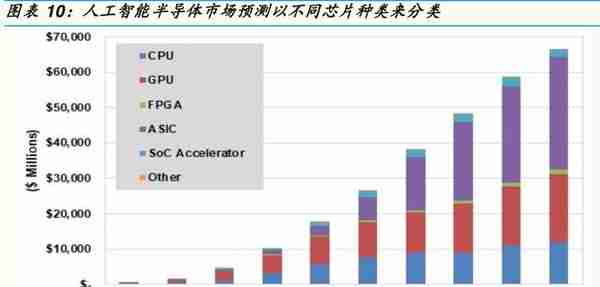
目前人工智能芯片仍多是以GPU, 张量处理器, 或FPGA+CPU 为主, 但未来ASIC将在边缘运算及设备端遍地开花,及逐步渗透云端市场,预估全球AI云端半导体市场于2018-2025年CAGR应有 37%,边缘运算及设备端半导体市场于2018-2025年CAGR应有 249%, 远超过全球半导体市场在同时间CAGR的5%, 占整体份额从2018年的1% 到2025年的10%,超过10倍数增长可期。
一、人工智能平台到底是工具还是应用?
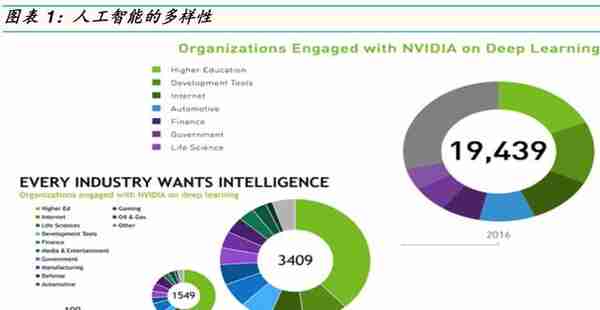
人工智能平台(包括芯片,模组,软件)在一般人看起来像是一种新型应用,但在我们看来人工智能芯片在整合软硬件后将成为各种物联网应用的提升效能工具平台,这就像我们常用的微软Office软件,微软Office软件是我们在办公室应付各种应用的生财工具,因此人工智能平台除了被广泛利用在云端大数据的深度学习训练和推断外,我们认为人工智能平台也将出现在各式各样的应用端的边缘设备,从英伟达公布的数字来看,早在2016年,公司就累计了7大领域(高等教育,发展工具,互联网,自驾车,金融,政府,生命科学)及19,439客户使用其深度学习的服务工具,配合软件和之前在云端大数据的深度学习训练和推断的数据成果库,来达到帮助使用者或取代使用者来执行更佳的智能判断推理。
虽然目前人工智能芯片仍多是以昂贵的图形处理器(GPU),张量处理器(Tensor Processing Unit),或现场可编程门阵列芯片配合中央处理器(FPGA+CPU)为主,来用在云端的深度学习训练和推理的数据中心,但未来特定用途集成电路(ASIC)将在边缘运算及设备端所需推理及训练设备遍地开花,及逐步渗透部分云端市场,成为人工智能芯片未来的成长动能,我们预估全球人工智能云端半导体市场于2018-2025年复合成长率应有37%,边缘运算及设备端半导体市场于2018-2025年复合成长率应有249%(请参考图表),远超过全球半导体市场在同时间的复合成长率的5%,整体约占全球半导体市场的份额从2018年的1%到2025年的10%。
二、人工智能会渗入各领域应用-无所不在
当大多数的产业研究机构把自驾车(Autonomous drive vehicle),虚拟/扩增实境(Virtual Reality/Augmented Reality),无人商店(Unmanned store),安防智能监控(Smart Surveillance System),智能医疗,智能城市,和智能亿物联网(Internet of Things,IoT)分别当作半导体产业不同的驱动引擎,国金半导体研究团队认为其实自驾/电动车,5G,虚拟/扩增实境,无人商店,安防智能监控,智能医疗,智能城市其实都只是人工智能亿物联网的延伸。
2.1无人驾驶/电动/联网车对半导体的需求爆增10倍
虽然全球汽车半导体产业,目前由传统的整合元件制造商(IDM)掌控,但未来很难说,主要是因为先进辅助或自动驾驶系统兴起,人工智能,摄像,传感,雷达芯片公司的出现。像英伟达图形处理器(Xavier,Pegasus320),谷歌张量处理器(Tensor Processing Unit),英特尔/Alt era/Mobil eye的CPU/FPGA/AI解决方案,地平线L3/L4自动驾驶(Matrix1.0平台,征程2.0芯片),高通,联发科,华为/海思的5G无线通信平台及毫米波雷达,索尼,豪威的传感器,博通及瑞昱的以太网络芯片。尤其是自动驾驶对雷达,摄像头,传感器及芯片的3倍增幅;千倍的3D视频数据的上传及云端的存储,学习,推理;因无人驾驶车设备及云端建制成本高昂(US$150,000/Way mo车),额外成本必须由广大消费者共同分摊费用较有利,乘坐共享,公交服务业,产品运送的后勤支援业无人驾驶应会领先乘用车市场,而Way mo/谷歌将带动出租车/公交车自动驾驶市场,领先英伟达的自驾乘用车市场(请参阅国金电动,无人驾驶,车联网的三部曲驱动力的深度报告),依照美国加州DMV(Department of Moter Vehicles)最新公布的资料显示Way mo于去年测试的120万英里中,每1000英里发生解除自驾系统状况频率是0.09次,运低于前年的0.179次,及通用Cruise的0.19次,苹果的872次,及Uber的2860次;自动泊车、车道偏离检测、无人驾驶的带宽需求,及车内电线费用和重量的不断增加。为了让增加数倍的电子控制单元(ECU)能彼此间快速地沟通,数倍的以太网路节点和转换器芯片需求便随之而来。
2.2无人商店及安防智能监控
除了自动驾车联网外,最近风起云涌的无人商店和智能监控,不也是利用大量监控摄像头,配合三维人脸辨识系统,二维码/近场通讯来收集大数据资料,再透过WiFi/xDSL/光纤传输,将资料送到云端人工智能储存与处理来达到无需柜台人员的无人商店和能随时辨识的视频智能监控,而政府机关可透过此系统来调查人口移动来重新设计城市智能公共交通系统,协寻通缉犯,恐怖分子,失踪人口,及在展场,车站,机场,学校,大型活动场地的安全监护;系统整合业者除可做无人商店外,也可靠着人口动向来预测消费热点(商家必备),人口居住热点(房地产业必备),如果再配合无人商店,线上购物系统,和政府的大数据,系统业者便可更精准的投送广告,发展个人信用评级。类似于自驾车联网,无人店和监控联网系统需要大量并且高清晰度的三维辨识摄像头和芯片,传输系统和芯片,和庞大的云端,边缘运算,及设备端的储存及智能训练及推理的各式高速芯片及软件。
2.3智能医疗
智能医疗系统可利用三维脸部个人辨识来挂号,减少排队时间,让看诊更顺畅。医院可收集资料并整合个人在不同医疗院所的所有医疗纪录;医生可利用人工智能数据平台辅助做更精准的医疗判断,减少重复用药的浪费和对病人的副作用,医院可利用此大数据资料做更深入的医学研究,数家政府医院应先抛砖引玉,带头做整合。
2.4智能亿物联网
(1) 空污,水污染化学感测物联网:政府是否应利用强制安装并定期检验各式气体/液体的物联网化学感测器在每部汽、机车和工厂排污管道上,再透过大量的低耗能无线通讯将资料上传到云端储存和处理,并透过人工智能来监测空污,水污来收取空污或水污税;
(2) 身份识别证明联网:大型互联网企业像谷歌(Googl US),百度(Baidu US),腾讯(00700.HK),或海康威视(002415.SZ)为何不能发展三维脸部个人辨识智能系统来整合所有的线上线下购物,启动驾驶,银行转帐/汇款/提款,进入手机/电脑/应用App,和政府机关办事所需要的身份证明。您可否想过你现在要纪录多少密码,多少使用者名称,身上带着多少付款软体,银行卡,信用卡,钞票,居民身分证,交通卡,驾照,护照,居民健康卡,电梯卡,加油卡,金融社保卡,大卖场会员证,和各式通行卡;
(3) 同步翻译连网:目前先进智能芯片/软体的语音辨识速度太慢和不够精准的理解与翻译,应是语言同步翻译机仍未大卖的主因,但透过更高速的智能芯片,无线通讯芯片和更庞大的语音数据库来训练云和端的人工智能的推理反应,相信未来国际多种语言的零障碍沟通将指日可待;
(4) 人工智能教师和消费机器人:当把强大的人工智能导入到人工智能教师和消费机器人联网物中,透过不断的反覆学习,这不但可提升学生的教育水平和兴趣,未来都能解决老人及残障人士的健康照顾,清洁,饮食,娱乐,保全等需求,减少后代的负担及外佣虐老事件,也明显能提升老人和残障人士的寿命和生活品质。
三、三种主流人工智能演算法
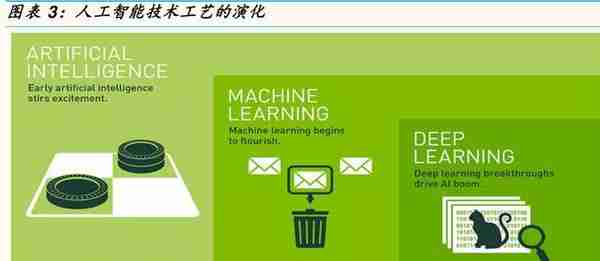
最早的人工智能出现及运用在1950-1980年代,接着转换到1980-2010年机器学习,从2010年以后,随着各种演算法CNNs,RNNs,DNNs等图影像视觉学习,辨识,推理的普及,让深入人工智能深入学习的突飞猛进。深度学习是人工智能和机器学习的一个子集,它使用多层人工神经网络在诸如对象检测,语音识别,语言翻译等任务中提供最先进的准确性。深度学习与传统的机器学习技术的不同之处在于,它们可以自动学习图像,视频或文本等数据的表示,而无需引入手工编码规则或人类领域知识。它们高度灵活的架构可以直接从原始数据中学习,并在提供更多数据时提高其预测准确性。人工智能的深度学习最近取得的许多突破,例如谷歌Deep Mind的AlphaGo及更强大的Alpha Zero陆续在围棋,西洋棋类比赛夺冠,谷歌Waymo,英伟达的Xavier/Pegasus320,及Intel/Mobil eye的Eye4/5自动驾驶汽车解决方案,亚马逊的Alexa,谷歌的Google Assistant,苹果Siri,微软的Cortana,及三星的Bixby智能语音助手等等。借助加速的深度学习框架,研究人员和数据科学家可以显着加快深度学习培训,可以从数天或数周的学习缩短到数小时。当模型可以部署时,开发人员可以依靠人工智能芯片加速的推理平台来实现云,边缘运算设备或自动驾驶汽车,为大多数计算密集型深度神经网络提供高性能,低延迟的推理。
3.1卷积神经网络CNNs(Convolutional Neural Networks)
卷积神经网络(CNN)是建立在模拟人类的视觉系统,并透过图影像分类模型的突破,也将是,主要来自于发现可以用于逐步提取图影像内容的更高和更高级别的表示。CNN是将图像的原始像素数据作为输入,并‚学习‛如何提取这些特征,并最终推断它们构成的对象。首先,CNN接收输入特征图:三维矩阵,其中前两个维度的大小对应于图像的长度和宽度(以像素为单位),第三维的大小为3(对应于彩色图像的3个通道:红色,绿色和蓝色)。CNN包括一堆模块,每个模块执行三个操作。举例而言,卷积将3x3过滤贴图的9个条件(0,1)套用(先乘后求和以获得单个值)在5x5输入特征贴图的9个像素特征上,而得出3x3全新的卷积输出特征贴图。在每次卷积操作之后,会采用最大池演算法(Max pooling),CNN对卷积特征贴图进行下采样(以节省处理时间),同时仍保留最关键的特征信息,最大池化是要从特征贴图上滑动并提取指定大小的图块(2x2),对于每个图块,最大值将输出到新的特征贴图,并丢弃所有其他值。在卷积神经网络的末端是一个或多个完全连接的层,完全连接的层将一层中的每个神经元连接到另一层中的每个神经元。它原则上与多层感知器神经网络(multi-layer perceptron neural network(MLP)类似,他们的工作是根据卷积提取的特征进行分类,CNN可以包含更多或更少数量的卷积模块,以及更多或更少的完全连接层,工程师经常试验要找出能够为他们的模型产生最佳结果的配置。总之,CNN专门于图影像处理如自动驾驶汽车,安防,人脸辨识,及疾病图像辨识解决方案。

3.2循环神经网络RNNs(Recurrent Neural Network)
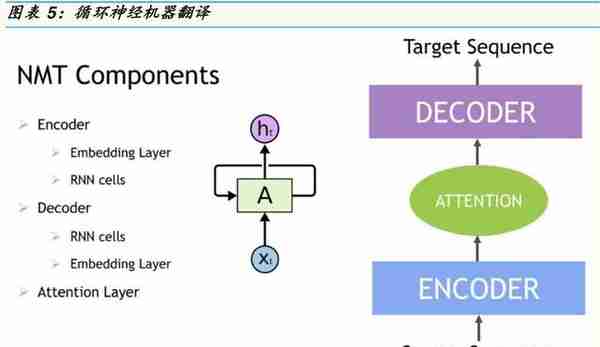
RNN是一类人工听觉及说话的神经网络,具有记忆或反馈回路,可以更好地识别数据中的模式。RNN是常规人工神经网络的扩展,它增加了将神经网络的隐藏层送回自身的连接-这些被称为循环连接。循环连接提供了一个循环网络,不仅可以看到它提供的当前数据样本,还可以看到它以前的隐藏状态。具有反馈回路的循环网络可以被视为神经网络的多个副本,其中一个的输出用作下一个的输入。与传统的神经网络不同,循环网络使用他们对过去事件的理解来处理输入向量,而不是每次都从头开始。当正在处理数据序列以进行分类决策或回归估计时,RNN特别有用,循环神经网络通常用于解决与时间序列数据相关的任务。不同于CNN专门于图影像处理,循环神经网络的应用包括自然语言处理,语音识别,机器翻译,字符级语言建模,图像分类,图像字幕,股票预测和金融工程。机器翻译是指使用机器将一种语言的源序列(句子,段落,文档)翻译成相应的目标序列或另一种语言的矢量。由于一个源句可以以许多不同的方式翻译,因此翻译基本上是一对多的,并且翻译功能被建模为有条件而非确定性。在神经机器翻译(NMT)中,我们让神经网络学习如何从数据而不是从一组设计规则进行翻译。由于我们处理时间序列数据,其中语境的上下文和顺序很重要,因此NMT的首选网络是递循环神经网络。可以使用称为注意的技术来增强NMT,这有助于模型将其焦点转移到输入的重要部分并改进预测过程。举两RNN的例子,为了跟踪你的自助餐厅主菜的哪一天,每周在同一天运行同一菜的严格时间表。如周一的汉堡包,周二的咖喱饭,周三的披萨,周四的生鱼片寿司和周五的意大利面。使用RNN,如果输出‚生鱼片寿司‛被反馈到网络中以确定星期五的菜肴,那么RNN将知道序列中的下一个主菜是意大利面(因为它已经知道有订单而周四的菜刚刚发生,所以星期五的菜是下一个)。另一个例子是如果我跑了10英里,需要喝一杯什么?人类可以根据过去的经验想出如何填补空白。由于RNN的记忆功能,可以预测接下来会发生什么,因为它可能有足够的训练记忆,类似这样的句子以‚水‛结束以完成答案。
3.3深度神经网络DNNs(Deep Neural Network)
DNN在视觉,语言理解和语音识别等领域取得了关键突破。为了实现高精度,需要大量数据和以后的计算能力来训练这些网络,但这些也带来了新的挑战。特别是DNN可能容易受到分类中的对抗性示例,强化学习中遗忘任务,生成建模中的模式崩溃的影响以及过长的运算时间。为了构建更好,更强大的基于DNN的系统,是能否有效地确定两个神经网络学习的表示何时相同?我们看到的两个具体应用是比较不同网络学习的表示,并解释DNN中隐藏层所学习的表示。设置的关键是将DNN中的每个神经元解释为激活向量,神经元的激活矢量是它在输入数据上产生的标量输出。例如,对于50个输入图像,DNN中的神经元将输出50个标量值,编码它对每个输入的响应量。然后,这50个标量值构成神经元的激活矢量。因为深度神经网路的规模(即层数和每层的节点数),学习率,初始权重等众多参数都需要考虑。扫描所有参数由于时间代价的原因并不可行,因而小批次训练(微型配料),即将多个训练样本组合进行训练而不是每次只使用一个样本进行训练,被用于加速模型训练。而最显著地速度提升来自GPU,因为矩阵和向量计算非常适合使用GPU实现。但使用大规模集群进行深度神经网路训练仍然存在困难,因而深度神经网路在训练并列化方面仍有提升的空间。
四、到底哪种人工智能芯片将成云计算的主流?
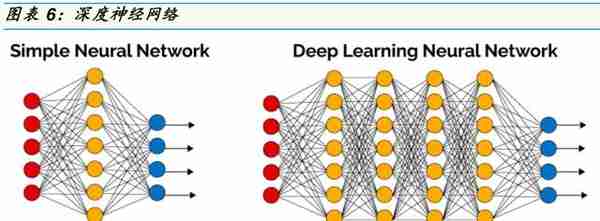
深度学习是一种需要训练的多层次大型神经网络结构(请参考图表),其每层节点相当于一个可以解决不同问题的机器学习。利用这种深层非线性的网络结构,深度学习可以从少数样本展现强大的学习数据集本质特征的能力。简单来说,深度学习神经网络对数据的处理方式和学习方式与人类大脑的神经元更加相似和准确。谷歌的阿法狗也是先学会了如何下围棋,然后不断地与自己下棋,训练自己的深度学习神经网络,更厉害的阿法零(Alpha Zero)透过更精准的节点参数,不用先进行预先学习就能自我演化训练学习。深度学习模型需要通过大量的数据训练才能获得理想的效果,训练数据的稀缺使得深度学习人工智能在过去没能成为人工智能应用领域的主流算法。但随着技术的成熟,加上各种行动、固定通讯设备、无人驾驶交通工具,可穿戴科技,各式行动、固定监控感测系统能互相连接与沟通的亿物联网,骤然爆发的大数据满足了深度学习算法对于训练数据量的要求。
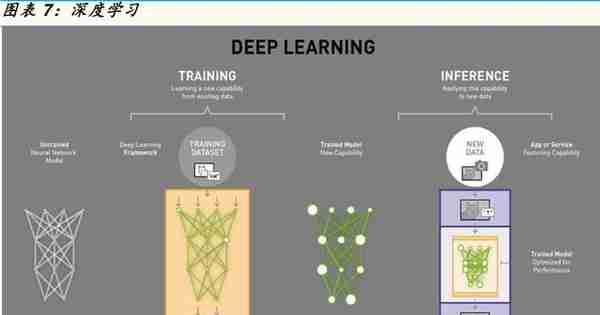
训练和推理所需要的神经网络运算类型不同。神经网络分为前向传播(Forward algorithm)其中包括输入层,隠藏层,输出层和后向传播(Backward algorithm)主要指的是梯度运算,两者都包含大量并行运算。训练同时需要前向和后向传播,推理则主要是前向传播。一般而言训练过程相比于推理过程计算量体更大。云端人工智能系统透过海量的数据集和调整参数优化来负责训练和推理,边缘运算终端人工智能设备负责推理。推理可在云端进行,也可以在边缘运算端或设备端进行。等待模型训练完成后,将训练完成的模型(主要是各种通过训练得到的参数)用于各种应用。应用过程主要包含大量的乘累加矩阵运算,并行计算量很大,但和训练过程比参数相对固定,不需要大数据支撑,除在云端实现外,也可以在边缘运算端实现。推理所需参数可由云端训练完毕后,定期下载更新到应用终端。
4.1在深度学习半导体领域里,最重要的是数据和运算
谁的晶体管数量多,芯片面积大,谁就会运算快和占据优势。因此,在处理器的选择上,可以用于通用基础计算且运算速率更快的GPU迅速成为人工智能计算的主流芯片,根据美国应用材料的公开资料(请参考图表),英伟达的人工智能逻辑芯片配合英特尔的中央处理器服务器芯片面积达7,432mm2,是不具人工智能的企业用和大数据服务器的八倍或谷歌专用张量处理器人工智能服务器的三倍多,存储器耗用面积(32,512mm2)是其他服务器的三倍以上。可以说,在过去的几年,尤其是2015年以来,人工智能大爆发就是由于英伟达公司的图形处理器,得到云端主流人工智能的应用。但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统的训练,可编程芯片FPGA的低功耗及低延迟性应有利于主导云端人工智能深度学习系统的推理,而特殊用途集成电路(ASIC)未来将主导边缘运算及设备端的训练及推理,但因为成本,运算速度,及耗电优势,也会逐步侵入某些特殊应用人工智能云端服务器市场,抢下训练及推理运算的一席之地,以下就先列出各种处理器在云端人工智能系统的优缺点:

4.2中央处理器CPU
X86和ARM在内的传统CPU处理器架构往往需要数百甚至上千条指令才能完成一个神经元的处理,但对于并不需要太多的程序指令,却需要海量数据运算的深度学习的计算需求,这种结构就显得不佳。中央处理器CPU需要很强的处理不同类型数据的计算能力以及处理分支与跳转的逻辑判断能力,这些都使得CPU的内部结构异常复杂,现在CPU可以达到64bit双精度,执行双精度浮点源计算加法和乘法只需要1~3个时钟周期,时钟周期频率达到1.532~3gigahertz。CPU拥有专为顺序逻辑处理而优化的几个核心组成的串行架构,这决定了其更擅长逻辑控制、串行运算与通用类型数据运算,当前最顶级的CPU只有6核或者8核,但是普通级别的GPU就包含了成百上千个处理单元,因此CPU对于影像,视频计算中大量的重复处理过程有着天生的弱势。
4.3图形处理器GPU仍主导云端人工智能深入学习及训练
最初是用在计算机、工作站、游戏机和一些移动设备上运行绘图运算工作的微处理器,但其海量数据并行运算的能力与深度学习需求不谋而合,因此,被最先引入深度学习。GPU只需要进行高速运算而不需要逻辑判断。GPU具备高效的浮点算数运算单元和简化的逻辑控制单元,把串行访问拆分成多个简单的并行访问,并同时运算。例如,在CPU上只有20-30%的晶体管(内存存储器DRAM dynamic random access memory,缓存静态随机存储器Cache SRAM,控制器controller占了其余的70-80%晶体管)是用作计算的,但反过来说,GPU上有70-80%的晶体管是由上千个高效小核心组成的大规模并行计算架构(DRAM和微小的Cache SRAM,controller占了剩下的20-30%晶体管)。大部分控制电路相对简单,且对Cache的需求小,只有小部分晶体管来完成实际的运算工作,至于其他的晶体管可以组成各类专用电路、多条流水线,使得GPU拥有了更强大的处理浮点运算的能力。这决定了其更擅长处理多重任务,尤其是没有技术含量的重复性工作。不同于超威及英特尔的GPU芯片,英伟达的人工智能芯片具有CUDA的配合软件是其领先人工智能市场的主要因素。CUDA编程工具包让开发者可以轻松编程屏幕上的每一个像素。在CUDA发布之前,GPU编程对程序员来说是一件苦差事,因为这涉及到编写大量低层面的机器码。CUDA在经过了英伟达的多年开发和改善之后,成功将Java或C++这样的高级语言开放给了GPU编程,从而让GPU编程变得更加轻松简单,研究者也可以更快更便宜地开发他们的深度学习模型。因此我们认为目前英伟达价值(6,000/7,500-9,300/10,500美元)的图形处理器加速卡TeslaV100PCIe/SXM2(640Tensor核心,5,120CUDA核心)或配备8/16颗V100的DGX-1/H-2系统(180,000-360,000美元),配合其CUDA软件及NV Link快速通道,能达到近125兆次深入学习的浮点运算训练速度(TERAFLOPS),以16bit的半精度浮点性能来看,可达到31TeraFLOPS,32bit的单精度浮点性能可达到15.7TeraFLOPS,及64bit的双精度可达到7.8TeraFLOPS,210亿个晶体管,台积电12纳米制程工艺,815mm2芯片大小,仍然是目前云端人工智能深入学习及训练的最佳通用型解决方案,但未来会受到类似于华为海思Ascend-Max910ASIC芯片及Ascend Cluster系统的挑战。
4.4现场可编程门阵列芯片FPGA的优势在低功耗,低延迟性
CPU内核并不擅长浮点运算以及信号处理等工作,将由集成在同一块芯片上的其它可编程内核执行,而GPU与FPGA都以擅长浮点运算着称。FPGA和GPU内都有大量的计算单元,它们的计算能力都很强。在进行人工智能神经网络(CNN,RNN,DNN)运算的时候,两者的速度会比CPU快上数十倍以上。但是GPU由于架构固定,硬件原来支持的指令也就固定了,而FPGA则是可编程的,因为它让软件与应用公司能够提供与其竞争对手不同的解决方案,并且能够灵活地针对自己所用的算法修改电路。虽然FPGA比较灵活,但其设计资源比GPU受到较大的限制,例如GPU如果想多加几个核心只要增加芯片面积就行,但FPGA一旦型号选定了逻辑资源上限就确定了。而且,FPGA的布线资源也受限制,因为有些线必须要绕很远,不像GPU这样走ASICflow可以随意布线,这也会限制性能。FPGA虽然在浮点运算速度,增加芯片面积,及布线的通用性比GPU来得差,却在延迟性及功耗上对GPU有着显着优势。英特尔斥巨资收购Altera是要让FPGA技术为英特尔的发展做贡献。表现在技术路线图上,那就是从现在分立的CPU芯片+分立的FPGA加速芯片(20nmArria10GX),过渡到同一封装内的CPU晶片+FPGA晶片,到最终的集成CPU+FPGA系统芯片。预计这几种产品形式将会长期共存,因为CPU和FPGA的分立虽然性能稍差,但灵活性更高。目前来看,用于云端的人工智能解决方案是用Xeon CPU来配合Nervana,用于云端中间层和边缘运算端设备的低功耗推断解决方案是用Xeon CPU来配合FPGA可编程加速卡。赛灵思(Xilinx)于2018年底推出以低成本,低延迟,高耗能效率的深度神经网络(DNN)演算法为基础的Alveo加速卡,采用台积电16nm制程工艺的Ultra Scale FPGA,预期将拿下不少人工智能数据中心云端推理芯片市场不少的份额。

4.5谷歌张量处理器TPU3强势突围,博通/台积电受惠,可惜不外卖
因为它能加速其人工智能系统Tensor Flow的运行,而且效率也大大超过GPU―Google的深层神经网络就是由Tensor Flow引擎驱动的。谷歌第三代张量处理器(TPU,Tensor Processing Unit,大约超过100TeraFLOPS/hp-16bit)是专为机器学习由谷歌提供系统设计,博通提供ASIC芯片设计及智财权专利区块,台积电提供16/12纳米制程工艺量身定做的,执行每个操作所需的晶体管数量更少,自然效率更高。TPU每瓦能为机器学习提供比所有商用GPU和FPGA更高的量级指令。TPU是为机器学习应用特别开发,以使芯片在计算精度降低的情况下更耐用,这意味每一个操作只需要更少的晶体管,用更多精密且大功率的机器学习模型,并快速应用这些模型,因此用户便能得到更正确的结果。以谷歌子公司深度思考的阿尔法狗及零(AlphaGo,Alpha Zero/Deep Mind)利用人工智能深度学习训练和推理来打败世界各国排名第一的围棋高手,世界排名第一的西洋棋AI程式Stockfish8,世界排名第一的日本棋Shogi AI专家,但我们估计Alpha Zero系统使用至少近5大排人工智能主机,5,000个张量处理器,1,280个中央处理单元而让云端的设备异常昂贵,且无提供任何的边缘运算端设备。
4.6 ASIC特定用途IC需求即将爆发
即使研发期长,初期开发成本高,通用性差,但国内芯片业者因缺乏先进x86CPU,GPU,及FPGA的基础设计智慧财产权(IPs),可完全客制化,耗电量低,性能强的特定用途IC(ASIC Application-specific integrated circuit)设计就立刻成为国内进入人工智能云端及边缘运算及设备端芯片半导体市场的唯一途径。但因为起步较晚,除了比特大陆的算丰(SOPHON)BM1680及BM1682云端安防及大数据人工智能推理系列产品已经上市之外,其他公司在云端人工智能训练及推理芯片设计都还停留在纸上谈兵阶段。举例而言,华为海思使用台积电7纳米制程工艺设计的昇腾Ascend910ASIC系列,号称在16bit半精度下能达到256兆次的浮点运算,倍数于英伟达目前最先进的Volta100解决方案(台积电12纳米)也要等到2H19量产及谷歌最新推出的张量处理器3(台积电16/12纳米),。而从智能手机端IP事业切入设计云端芯片的寒武纪,将于2019首发的产品MLU100PCIe智能推理加速卡(台积电16纳米)在打开稀疏模式时的峰值也可达到64兆次浮点运算(16bit半精度)。最后可惜的是国内搜寻引擎龙头百度的昆仑芯片(818-300采用Samsung14纳米),阿里巴巴的Ali-NPU,及亚马逊的Inferentia目前都还没有提供更确实的芯片速度,耗电量,应用,价格,量产时点,及软件框架规格让我们做出更好的比较图表。
五、哪种人工智能芯片将成边缘运算及设备端的主流?
从算法,IP,边缘运算及设备端芯片转换到模块,平台或生态系的战争。
谷歌在GoogleCloudNEXT2018活动中,首次推出人工智能推断用边缘运算张量处理器(Edge Tensor Processing Unit,Edge TPU,<30mm2)具有低功耗,低延迟,高运算效率,其开发版系统模块套件中还包括有恩智浦的CPU,图芯的GPU,再配合谷歌开源简易版机器学习框架软件(Open-source Tensor Flow Lite),设备端物联网核心运作(Edge IoT Core)和边缘运算端张量处理器,来推动各种应用,像是预测性维护,异常检测,机器视觉,机器人,语音识别,医疗保健,零售,智能空间,运输交通等等。

在谷歌的Waymo建立了全球最大的无人驾驶车队后,谷歌再次利用其在深度学习及云端软,硬件的技术领先优势,提供机器学习边缘运算端软件,固件,安卓物联网作业系统及专用半导体芯片整体解决方案模块,让客户对其智能物联网解决方案的黏着度提升,这不但对中国大陆人工智能芯片公司是利空,也对目前主要提供云及边缘运算物联网服务的竞争厂商亚马逊(AWS),微软(Azure),阿里巴巴造成市场压力。
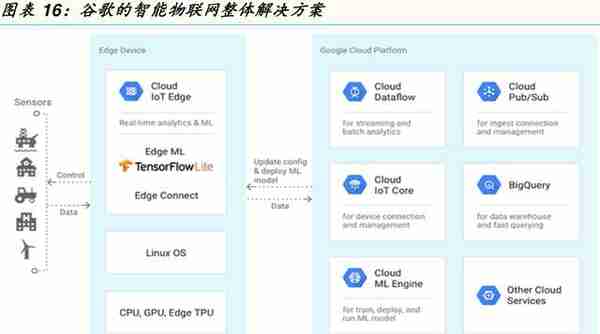
但是,目前谷歌终端型张量处理器目前只能算是个机器学习的加速器,不能独立运作,其解决方案中还要配合其他半导体公司的芯片,像是恩智浦以安谋为核心的中央处理器,图芯(Vivante Corporation)的GC7000Lite图形处理器(请参考图表),我们认为谷歌的解决方案效能比较与量产时间未定。而且,谷歌过去还是主推软件解决方案,自有硬件及半导体的产品上市都是拿来推广其软件及生态系解决方案,其边缘运算型张量处理器硬件规格中,还是使用相对旧的28纳米晶圆代工制程工艺,TeraOPS浮点远算能力,耗电瓦特数,价格等指标都还是未知,来与其他人工智能芯片设计公司的产品来做比较。举例而言,英伟达今年推出的Jetson AGXX avier模块也是瞄准物联网应用端的解决方案,但在其高单价下规格明显胜出。华为即将推出的边缘运算模块Atlas200和Atlas300也相当有竞争力。
从英伟达,谷歌,英特尔,及华为在深入学习边缘运算端解决方案模块及软件与固件的竞争,而高通及联发科陆续将人工智能专利区块透过嵌入式整合到其手机应用处理器中,可以看出未来在人工智能端的应用领域已经不再单单是人工智能算法,IP(智财权)到芯片设计推陈出新的竞争,中国大陆的人工智能算法/IP/芯片龙头公司像寒武纪,地平线为了存活,就必须与应用领域系统公司紧密合作,共同推出更佳的嵌入式或独立式解决方案模块及软,固件,否则就要像谷歌和英伟达一样推出自己整套的解决方案。虽然比特大陆及嘉楠耘智进入人工智能芯片领域较晚,但其在挖矿机业务及挖矿生态系的系统整合经验,反而比只具备算法/IP/芯片的人工智能设计公司还有机会。
六、谁能引领国内人工智能芯片产业突围?
未来因人工智能边缘运算推理端和云端推理(Inferencing)芯片及设备成本,性能,耗电,效率的考量,以及各种处理器的特性不同,我们预期特定用途集成电路(ASIC)或系统集成电路(SoC,system on chip)未来将在设备,边缘运算,及云端推理市场和设备,边缘运算,小部分云端训练市场遍地开花,百花齐放,根据产业链调查,我们认为中国在处理器/芯片领域的投资有加速的迹象,AI芯片的创业企业目前已达到40家左右。
而中国的人工智能半导体公司像华为海思(HiSilicon),寒武紀(Cambricon),地平线(Horizon Robotics),彼特大陆(Bitmain),耐能(Kneron),肇观(Next VPU),及大数据系统公司如百度,阿里巴巴及安防龙头海康威视,大华将追随国际大厂陆续推出人工智能特定用途集成电路和系统芯片,从过去的模仿和追赶模式改为提前布局的思路,加上今年中国科创板融资平台的加持,相信一定可以孵育出未来世界级的人工智能芯片设计龙头公司。但就未来2-3年来看,因为有强大的财物资源来支持10纳米以下先进制程工艺的电子设计自动化软件(EDA tool),验证(Verification),光掩膜(Photo Mask)成本的蹿高(请参考图表),最有实力的半导体设计团队,及其对人工智能深入学习系统的知识及各种设备人工智能化的需求,我们预测华为海思将能引领国内人工智能芯片产业突围;而比特大陆因为深谙IP,芯片,模块,到平台或生态系的争战,金准产业研究团队不排除比特大陆反而领先其他一些一线设计公司率先推出些云端人工智能的推理/训练芯片及解决方案模块;当然,金准产业研究团队还是认为纯算法及半导体设计公司寒武纪,目前有较佳的设计团队及较充裕的估值融资能力来陆续推出边缘运算端及云端推理的人工智能芯片;最后因为SAELevel4/5自动驾驶平台成本过高及生态系组成庞大及复杂,目前金准产业研究团队对地平线在自动驾驶的解决方案方面的短期营运及获利模式存疑。

6.1华为海思后发先至
在供应全球智能手机第二大厂,中国智能手机第一大厂华为超过近六成的应用处理器及基频芯片,及率先数月于高通及联发科采用台积电的7纳米制程工艺推出的麒麟980芯片,让华为的Mate20手机大卖,并让华为整体智能手机在国内的市占从2017年的20%,提高到2018年的27%,及2018年四季度的29%,预期这也将同时拉升华为海思(HiSilicon)在全球无晶圆设计公司的市占到6-7%或是在2019年成为前五大。而7纳米的麒麟980芯片是整合了寒武纪(Cambricon)设计的Cambricon-1M神经处理单元(NPU,Neural Processing Unit)专利区块来让摄像头看得更全,更清,更快,更久,让麦克风听得更清,更广,识别场景,推测用户行为意图,和适时处理高性能或高效率任务,根据华为公布的资料,在人工智能性能比上,其NPU是一般CPU的25倍,GPU的6.25倍(25/4),能效比上,NPU更是达到了CPU的50倍,GPU的6.25倍(50/8)(请参考图表)。但因为目前其边缘运算端神经处理单元架构简单,金准产业研究团队估计此专利区块芯片应不超过整体芯片面积(基频和应用处理器整合在一起的系统芯片面积)的10%。但因为金准产业研究团队预期采用台积电7纳米EUV制程工艺的华为海思麒麟990芯片,将使用海思自行设计的人工智能专利区块Ascend Lite SKU(请参考图表),而苹果(Neural Engine,5TeraOPS)高通(Neural Processing Engine SDK Software Development Kit,<8TeraOPS),联发科(Neuro Pilot SDK,Android Neural Network NNAPI联发科Neuro Pilot SDK)也将陆续整合其人工智能专利区块及软件到其手机应用处理器(Application processor)中,这将对寒武纪及其他人工智能算法及芯片公司在智能手机及联网物(IoT)设备端的芯片发展造成限制。
华为海思因为有这样强大的财物资源来支持7纳米以下先进制程工艺的电子设计自动化软件(EDA tool),验证(Verification),光掩膜(Photo Mask)成本的蹿高,拥有国内最强的半导体设计团队,及其庞大的系统知识及各种设备对人工智能化的需求,金准产业研究团队预测华为海思将后发先至引领国内人工智能芯片产业突围。华为海思今年将陆续问世的7纳米昇腾Ascend-Max910ASIC(整合8颗芯片dies),及1,024颗昇腾910芯片的Ascend Cluster(256PetaFLOPS),使用12纳米昇腾Ascend-mini(310),-Lite,-Tiny,-Nano ASIC推出的Atlas200加速模块,Atlas300加速卡,Atlas500智慧小站,Atlas800私有云解决方案一体机,MDC600移动数据中心(Mobile Data Center)。金准产业研究团队预期这些AI芯片及系统,陆续将对英伟达,赛灵思,英特尔,谷歌在云端及边缘运算端人工智能芯片及平台的地位,带来挑战,但特定用途IC的专用性缺点会让华为海思切入像是外部安防等系统公司客户时,碰到些安防公司系统知识领域不愿意外泄的问题。
6.2寒武纪从设备端步入云端
寒武纪(Cambricon)是于2016年在北京成立,核心成员陈天石及陈云霁兄弟都曾在中科院计算所工作,专攻计算机处理器结构优化和人工智能,而后来寒武紀在拿到中关村科技园区支持资金及上海市政府对神经网络处理器,深度学习处理器IP核项目,智能处理器核项目等多项补助近6,000万人民币,加上多次拉高估值的融资,于2018年5月3日,发布了使用TSMC7nm工艺IP的1M,每瓦速度达3.1-3.3兆次运算,为10纳米1A智财权专利区块的10倍左右,且超越英伟达V100的每瓦速度达0.4兆次运算,其8位运算效能比达5Tops/watt(每瓦5兆次运算)。寒武纪提供了三种尺寸的处理器内核(2Tops/4Tops/8Tops)以满足不同领域下,不同量级智能处理的需求(智能手机、智能音箱、摄像头、自动驾驶)。Cambricon也介绍以TSMC16nm工艺制程设计的MLU100及MLU200云端服务器AI芯片,具有很高的通用性,可满足计算机视觉、语音、自然语言处理和数据挖掘等多种云端推理,甚至训练的任务。在发布会上,联想(ThinkSystemSR650),中科曙光(Phaneron服务器),科大讯飞(翻译机2.0)都介绍了使用CambriconMLU100芯片相对应的云端服务器。此外,专为开发者打造的Cambricon Neu Ware人工智能软件平台,加上支持Tensor Flow,Caffe,MXNet等主流机器学习框架(Framework),让寒武纪在尚未扭亏为盈的情况下(估计2017年亏损超过1,000万人民币以上),2018年营收连1,000万美金都达不到的状况下(2016/2017年营收估计约400万人民币上下),市值已被拉高到超过25亿美元。
6.3卖人工智能解决方案模块的地平线
地平线(Horizon Robotics)创办人是前百度深度学习研究院负责人余凯、还有前华为芯片研发架构师周峰,地平线不是只做芯片,在软件方面,地平线已经研发出了自动驾驶的雨果神经网络OS平台及智能家居的安徒生平台。地平线的目标是做分支处理单元(BPU,Branch processing unit)的人工智能算法架构+嵌入式芯片的(Embedded ARM,CPU,GPU,FPGA)自动驾驶(征程2.0处理器),智能城市,智能商业(旭日1.0处理器)的人工智能设备终端解决方案模块(具有感知,识别,理解,控制的功能)给产品厂商。地平线的整个流程是根据应用场景需求,设计算法模型,在大数据情况下做充分验证,模型成熟以后,再开发一个芯片架构去实现,该芯片并不是通用的处理器,而是针对应用场景跟算法是结合在一起的人工智能算法处理器,得到芯片大小,执行,耗能(Area、Performance、Power)的综合解决方案。地平线BPU架构的解决方案只可以用在符合车规的FPGA或GPU等计算平台上,下一步地平线会将自己的BPU处理器IP授权给国际厂商,让他们生产车规级处理器。智能驾驶方面,基于高斯架构研发的ADAS产品(征程1.0处理器)也会作为重点推进,SAEL3/L4的无人驾驶Matrix1.0平台,也会持续落实与系统厂商像是博世的技术合作,计划在年中实现特定道路的自动驾驶;智能生活方面,除与美的的合作之外,地平线继续在家电、玩具、服务机器人等领域发力;公共安防方面,地平线去年与英特尔在北美安防展上进行联合展示。类似于寒武纪,地平线于2018年11月27日获得近10亿美金的B轮融资,持续拉高其市值。
6.4从挖矿机转云端人工智能推理模块的比特大陆
由CEO詹克团及创办人吴忌寒于2013年联合成立的挖矿机及芯片霸主比特大陆(BITMAIN)于2017年11月,正式介绍其AIASIC芯片品牌SOPHON(算丰),宣布全球首款云端安防及大数据人工智能推理系列的张量加速计算芯片28nmBM1680的震撼面世,并展示了视频图像分析、人脸人体检测的演示。并同步发布了SOPHON.AI官网,并将系列产品在官网中面向全球发售。BITMAIN致力于通过强大的芯片工程、快速迭代和系统设计制造能力,提供最具性价比、最具性能功耗比的AI计算力,同时致力于为行业定制、优化全栈的硬件和系统方案,从而极大降低行业+AI的难度,促进AI普及。BM1682在2017年12月已进入流片阶段,并于2Q18量产。12nm的BM1684是预计于1Q19量产及第四代的12纳米芯片BM1686是预计于2H19量产。这两款芯片会拥有6/9TeraFlops的能力和30W的功耗。BM1880是比特大陆于2018年10月发布的一款设备端AI芯片,将主要应用于安防、互联网及园区等领域BM1880芯片可以作为深度学习推理加速的协处理器,也可以作为主处理器从以太网接口或USB接口接收视频流、图片或其它数据,执行推理和其他计算机视觉任务,其它主机也可以发送视频流或图片数据给BM1880,BM1880做推理并将结果返回主机。比特大陆将于2019年推出第二代产品BM1882,以及2020年的BM1884,按照规划,BM1882和BM1884的主要应用场景将是智能摄像机、智能机器人和智能家居等。虽然目前比特币跌破4,000美元以下,占比特大陆98%的矿机销售,自营挖矿业务要是采用两年折旧几乎是无利可图(除了于4Q18推出的7纳米BM1391挖矿芯片及S15挖矿机应可获利外),而AI芯片导入云端系统又遥不可期,但不同于其他新兴AI芯片设计公司大多缺乏现金,比特大陆在手现金(7-8亿美元现金,4-5亿美元的加密货币)应该还是有超过10亿美元,芯片研发设计资源仍然丰厚,每一代芯片代与代之间的间隔是快于摩尔定律而达到9-12个月。摩尔定律是指芯片行业每18到24个月的周期里,计算能力能翻一倍,或者在相同的单位芯片面积里,晶体管数量翻一倍。
6.5耐能专注于低功耗设备端的人工智能芯片
耐能(kneron)是由一群留美华人于2015年成立于圣地牙哥,CEO刘峻诚博士是毕业于UCLA,并于2018年7月延揽前高通多媒体研发部总监李湘村(前展讯,华为,VIVOVP)为其首席科学家,其余团队成员多有UCLA,清华大学,高通,三星电机,电子,计算机背景,并于2017年11月,耐能宣布完成超过千万美元的A轮融资,阿里创业者基金(Alibaba Entrepreneurs Fund)领投,奇景光电(HIMX,Himax Technologies,Inc.)、中华开发资本(CDIB)、高通、中科创达(Thunder soft)、红杉资本(Sequoia Capital)的子基金Cloudatlas,与创业邦跟进投资,2018年5月由李嘉诚旗下维港投资(Horizons Ventures)领投的A1轮融资,还有最近一轮从Iconiq capital(Mark Zuckerberg’sprivate fund)拿到的融资。耐能的定位是子系统设备端人工智能的技术提供厂商,现在主打低功耗、轻量级,可压缩/重组(recon figurable,靠软件重组CNN,Pooling运算区块的组合)的NPU(神经网络处理单元)芯片,专注在智能手机的子系统(NPUIP-KDP300)、物联网(IoT)、智能家居、智能安防(NPUIP-KDP500)设备端市场,机器人,无人机,安防(NPUIP-KDP700)能耗比可以做到100mw到300mw,最新的一款产品甚至可以到10mw以下,但在算力方面可以达到华为海思Ascend Lite系列的芯片等级,而纳能另外与Cadence的TensilicaVisionP6DSP处理器整合的KDP720NPU处理器,主要是锁定智能安防与监控。有别于目前市场上主流的云端人工智能,耐能提供创新的设备端人工智能解决方案,可将一部份的人工智能从云端移转到设备端上,进行实时识别与分析推断,不用等到把所有数据经由网络传送至云端后才能处理,并可大幅减轻网络、云端的负担与成本。耐能目前手机加OEM/ODM客户可达6-8家,主要客户有手机相关的高通,格力,奇景光电,互联网的客户包括搜狗,腾讯,钰创,钰立微,工业计算机客户有研扬,安防客户有大华,苏州科达等。格力已经使用其智财权区块量产,目前一些芯片已经量产。因扩大研发团队及产品线,耐能从2017年的获利扭赢转到2018年亏损达400-500万美元,但2019年将有二颗芯片流片(Tapeout)。
6.6亿智是有实力又低调的AI芯片公司
由前全志团队组成的亿智电子科技于2016年7月在珠海高新区注册成立。同年10月在北京设立人工智能(AI)算法研究团队。亿智核心团队是中国最早一批进行SOC系统设计的专家,有20多年的行业经验,目前亿智在珠海的研发团队已近100余人。亿智电子科技已于2018年2月完成了数千万元天使轮融资,并于2018年8月由北极光创投领投,达泰资本跟投。亿智的商业模式主要为代理商和大客户提供整套的解决方案。目前,亿智解决方案主要聚焦在视像安防、智能硬件(家电)、汽车电子等方面。2017年底第一颗Test Chip首次流片即成功,2018年第四季度流片AI功能量产版系统级芯片,于2019年实现量产出货。亿智在珠海、北京、深圳均设有办公地点,其中珠海为总部,负责芯片设计、算法研究、软件开发等方向。北京负责人工智能AI算法的研究。深圳负责方案开发、技术支持、市场与客户拓展等。亿智成立至今,一直坚持AI加速、高清显示、音视频编解码、高速数模混合等IP的自主研发,这样可以实现更低带宽、更低功耗、更低成本地落地应用产品。特别是AI的IP的PPA指标均优于业界对手。目前已经成长为具备完全自主AISOC产品量产落地能力的人工智能芯片设计公司。亿智凭借在音视频编解码以及AI视觉算法方面积累了超过10年的领先经验,通过对人工智能需求市场的垂直化、场景化应用研究,在汽车电子应用方面,亿智的产品线具有车牌识别、路牌识别、文字识别的能力,ADAS智能算法可实现4路全景拼接、全景泊车,行车记录仪/智能后视镜/智能中控车机等汽车电子产品应用。目前的夜视后视镜产品,长焦夜视摄像头、短焦行车摄像头,显示车辆油耗、车速、水温等,信息全部手机互联。4G后视镜提供在线导航、在线音乐、云狗、行车记录,ADAS安全驾驶辅助系统。亿智的占道抓拍产品,可进行车牌检测,车牌识别,抓拍路段时间规划、黑白名单管理、车辆轨迹显示、后台管理系统多车道实时识别,具备软件能力,团队表示目前的识别成功率达到95%。志在成为视像安防、汽车电子、智能硬件领域智能化(AI)赋能的全球领导者。
结语
金准产业研究团队分析,有今年中国科创板融资平台的加持,国内的半导体公司将陆续推出人工智能ASIC抢先机。而华为海思因为有强大的财力来开发10纳米及以下产品,负担EDA软件,验证,光掩膜成本的蹿高,加上强大的设计团队及对系统的认知,预计将引领国内AI芯片行业突围;而比特大陆因为深谙IP,芯片,模块,到生态系的竞争,不排除其反而率先推出有竞争力的云端人工智能的解决方案模块;寒武纪目前有较佳的设计团队及较充裕的估值融资能力来陆续推出边缘运算端及云端推理的人工智能芯片。
除了国内算法软件公司及美国AI芯片大厂外,未来24个月,我们看不出来国内AI芯片大厂能摆脱亏损;美国商务部工业安全局可能对其11项AI和机器学习技术列入出口管制清单;AI ASIC大厂对各种应用系统认知不足,安防/语音/自驾系统公司不愿分享其系统设计机密。
推荐阅读

-
企业币和虚拟货币?有什么本质区别吗?
1970-01-01
但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统...
-
不是虚拟货币可以赚钱吗 你身边有没有玩虚拟币的人。他们都有挣到钱了吗?
1970-01-01
但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统...
-
虚拟币挖矿交易平台(虚拟货币挖矿是什么意思)
1970-01-01
但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统...
-
虚拟货币合约交易软件下载 巅峰极速合约150个合约币怎么获得
1970-01-01
但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统...
-
虚拟币平台哪个好用(虚拟币平台哪个好用点)
1970-01-01
但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统...
-
北交所换虚拟货币(北京证券交易所的落地将带来哪些机遇?有什么影响和意义?)
1970-01-01
但未来因为各个处理器的特性不同,我们认为英伟达的图形处理器GPU和谷歌的张量处理器仍能主导通用性云端人工智能深度学习系统...